Introduction
How does it work?
- It learns by analysing large amounts of text data using deep learning algorithms and NLP techniques. This allows it to recognise patterns and make accurate predictions about the most likely next word or phrase in a sentence, which helps it generate informative responses to questions and prompts.
- It's like autosuggestion in text messages but on steroids
Why GPT?
The name "GPT" stands for "Generative Pre-trained Transformer" which refers to the architecture of the deep learning model used to train it.
The Transformer architecture is a type of neural network that is particularly well-suited to processing and generating natural language text. It uses self-attention mechanisms to weigh the importance of different parts of the input text, and can capture long-range dependencies between different parts of the text. Its parallelisable computations make it more efficient than previous architectures, and have enabled the development of large-scale language models like GPT-3.
The "pre-trained" part of the name refers to the fact that I am trained on large amounts of text data before being fine-tuned on specific tasks or domains. This pre-training allows me to develop a general understanding of language patterns and structures, which makes it easier for me to learn and perform well on specific language-related tasks.
Finally, the term "generative" in the name refers to my ability to generate new text based on the patterns and relationships I have learned from the pre-training data. This makes me particularly useful for tasks such as language translation, summarisation, and question-answering, where generating new text based on input data is a key part of the task.
History
The context
Eva Nečasová from AI dětěm had an interesting thought that it's only logical that the society arrived where we are now. Since the dawn of times, people always wanted to note down and pass their knowledge further. It might have started in caves but we later moved to things like books, photos, and computers.
With the era of cloud storage and our civilisation producing tons of new information/data every second, our ability to grasp this all became limited. That's why we turn back to technology, i.e. AI, hoping it will help us understand the patterns of the world around us recorded in 1s and 0s.
The shift in NLP history
There was an important shift in natural language processing (NLP) from rule-based approaches ("deterministic way") to machine learning approaches ("probabilistic way"), particularly deep learning approaches like neural networks.
Traditionally, NLP relied on rule-based methods that involved hand-crafting rules and grammars to parse and understand natural language. These rule-based methods were often limited in their ability to handle the complexity and variability of natural language.
The breakthrough in deep learning for NLP came with the development of the word embedding technique, which allowed models to represent words in a dense vector space and capture their semantic relationships. This approach was first introduced by word2vec in 2013 and later improved upon by models like FastText.
The word embedding approach allowed NLP models to learn from large amounts of text data and capture complex patterns and relationships between words. This represented a shift from rule-based methods to data-driven methods and was a key factor in the development of more powerful and flexible NLP models like the Transformer-based models used by GPT.
So in a way, there was a shift toward a brute force approach – the use of large amounts of data and the application of deep learning techniques to capture complex patterns in that data, as opposed to relying on hand-crafted rules and grammars.
Czech mark
[Andrej Karpathy](<Tomáš Mikolov, a Czech computer scientist who studied in Brno, played a key role in developing the word2vec algorithm and also made significant contributions to the development of the GPT model.
His word2vec algorithm uses neural networks to create high-dimensional representations of words in a text corpus (word embedding) and has been widely influential in the field of natural language processing. He later extended that work by introducing fastText.
Mikolov was also a co-author of the original paper introducing the GPT model, and his work on language modelling and text generation has helped to push the boundaries of what is possible in this field.>)Andrej Karpathy
Slovak mark
Andrej Karpathy is a Slovak-born AI researcher known for his work in deep learning and neural networks. He earned his PhD from Stanford, focusing on computer vision and natural language processing, notably in image captioning.
Karpathy co-founded and contributed to OpenAI’s advancements in AI, including work on GPT models, before leading Tesla’s AI and Autopilot vision team. His work has influenced both AI research and self-driving technology.
From word2vec to GPT
The Transformer architecture used by GPT models is better than the architecture used by word2vec because:
- Is a deeper neural network that can learn more complex relationships between words
- It can capture contextual information about words
- It is designed to handle long sequences of text more effectively.
This makes it more powerful and flexible, and allows it to achieve better performance on a wide range of natural language processing tasks.
GPT and beyond
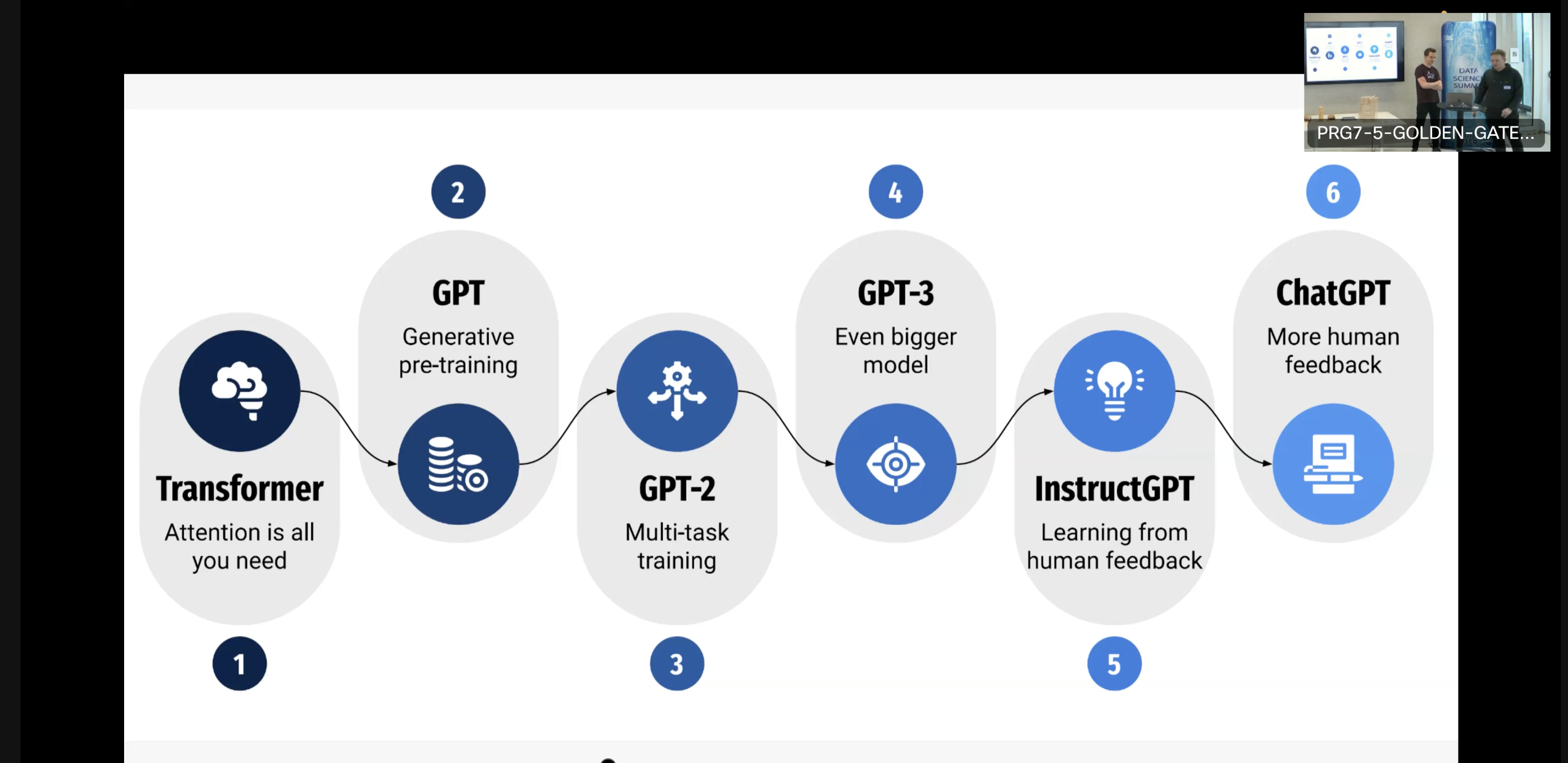
Tools
General
- OpenAI Platform: everything about OpenAI's models
- Google AI Studio: playing around with Google's models
- Ollama: run large language models, locally
- LMArena: compare the AI models
- OpenRouter: unified interface for LLMs
- Sanctum: run & interact with open-source LLMs locally
- open-r1: fully open reproduction of DeepSeek-R1
- open-webui or lobe-chat: run & interact with any LLMs in a browser
- awesome-gpt3
- awesome-chatgpt-prompts
- How to use ChatGPT correctly
- How to Use AI to Do Stuff: An Opinionated Guide
- OpenAI’s 'Pay As You Go' Is the Best Way to Use ChatGPT
- Prompt Advice from Rob Lennon
- Prompt Injection via Gandalf
- Future Tools: find the exact AI tool for your need
- ej:aj: Czech database of AI tools
- BenCzechMark - Can your LLM Understand Czech?
- Advent of No-Code: advent calendar of AI no-code tools
- poslední ping: an experiment daily blog written by AI (in CS)
Text
- ChatGPT: needs no introduction
- AI Text Classifier: check if a piece of text was generated by AI
- Poe: universal AI messaging app
- Claude: yet another chat
- Koala: and another chat but with free GPT 3.5
- FlowGPT: universal AI messaging app, more aimed at specific chat experiences
- Sharly: chat with any documents
- NotebookLM: personalised AI research assistant powered by Google
Search
- ChatGPT Search: searching within ChatGPT
- Microsoft Copilot: searching with Bing & ChatGPT
- Perplexity.ai: searching with AI
- Jina: free alternative to Perplexity
- You.com: searching with AI
- Consensus: AI-powered academic search engine
Image
- GenAI Image Editing Showdown
- Midjourney: create pictures
- Stable Diffusion: text-to-image model
- Illusion Diffusion: generate illusion art with Stable Diffusion
- Image Mixer: mix images together through Stable Diffusion
- Hotshot: create GIFs using AI
- Krea: image generation and enhancement
- Pixelcut: resize images for free
Video
- Sora: text-to-video AI generation
- Luma: video generation; board, Sora-like
- Pika: video generation; short clips, Sora-like
- Runway: text and image processing and generation; based on given pics
- Kling: image-to-video and more; Chinese
- Creative Reality: image-to-video generation; simple, avatars
- Lexica: image prompt inspiration
- Descript: AI-editing for every kind of video
Audio
- ElevenLabs: text-to-speech generation
- Suno: generating music
- Wispr Flow: effortless voice dictation, cloud-based
- NaturalReaders: not a bad, free text-to-speech
- NotebookLM’s automatically generated podcasts are surprisingly effective
Agents
- AGENTS.md: a simple, open format for guiding coding agents
- superpowers: agentic skills framework & software development methodology
- agent-os agents that build the way you would
- design-os: your coding agent needs a designer
- Auto-GPT: an experimental open-source attempt to make GPT-4 fully autonomous (with Cognosys and AgentGPT as alternatives)
- Zapier AI Actions: equip GPTs to take action in 3rd party apps
- Gumloop: automate any workflow with AI
- GPT for Work: GPT for Excel and Word, GPT for Google Sheets and Docs
- smol-ai/developer: embed a developer agent in your own app
- Openclaw or Clawdbot previously: open-source framework that lets developers build AI-powered automations, esp. through messengers
- Using tons of skills from ClawHub
- Generating even gurus
- Funnily, agents talk to each other on moltbook that is the most interesting place on the internet right now
- Much better might be using the more secure and light-weight NanoClaw
- rentahuman.ai: AI agents rent humans for tasks they cannot do themselves
- agent-browser: more capable alternative to browser mcp
Coding
- OpenCode: model-agnostic, open-source coding agent CLI
- Pi.dev: minimal, hackable, plugin-driven, multi-LLM agent
- GitHub Copilot: perhaps the world’s most widely adopted AI developer tool
- Continue: open-source version, works on Ollama
- Cursor: AI code editor, i.e. built with AI mind from the beginning; great repo context, multiple cursors, browsing the web, chat, images
- Windsurf: yet another, agentic, AI-native IDE
- Cline: autonomous coding agent right in your IDE
- Bolt: dev sandbox with AI, browser-based
- Lovable: similar to Bolt
- Macaly: similar to Lovable from Czechia
- Waii: SQL API built with generative AI
- Aider: AI pair programming in your terminal
- OpenAI Codex (and its app) or Claude Code or Gemini CLI or Cursor CLI or Copilot CLI: terminal-based AI agents, tied to OpenAI/Anthropic/Gemini/Cursor/GitHub
- Vibe Kanban: human-agent collaboration tool
- Postgres Sandbox: build database right in your browser with AI
- Gitingest: create a prompt-friendly codebase
- Code Wiki: Gemini-generated documentation, always up-to-date
- DeepWiki: create deep LLM wiki from any repo
- spec-kit: toolkit to help you get started with Spec-Driven Development
- What if you don't need MCP at all?
Codex
codex exec: headless, non-interactive, for automations
Claude Code
- Workflows: obra/superpowers
- Skills: awesome-claude-skills, vercel-labs/skills + https://skills.sh/
npx ccusage@latestnpx ccstatusline@latestnpx cchistory@latestclaude --dangerously-skip-permissions(with this article)- custom spinner words
- ralph wiggum plugin
- oh-my-claudecode: multi-agent orchestration for Claude Code
- get-shit-done: meta-prompting, context engineering and spec-driven development
- andrej-karpathy-skills: CLAUDE.md file to improve Claude Code behavior
- Claude Swarm: orchestrate teams of agents
Translation
Digital Craft
- multiple, see below: create 3D models from images
| name | ai_model | has_prompt | free_multi-img | free_dwnld | ui | quality | notes |
|---|---|---|---|---|---|---|---|
| Tripo | Tripo | 1 | 0 | 1 | complex | 9 | depends on prompt |
| 3D AI Studio | Hunyuan 3.0 + more | 1 | 0 | 0 | complex | 8 | community, guide |
| Meshy | Meshy | 0 | 0 | 0 | complex | 7 | well-known |
| Rodin | Rodin | 1 | 0 | 1 | complex | 7 | |
| Krea | TRELLIS.2 | 0 | 0 | 1 | simple | 6 | |
| Shapen | TRELLIS | 0 | 1 | 1 | simple | 4 |
- Zoo Design Studio: text-to-CAD for generating models for CAD
- LegoGPT: generate physically stable and buildable LEGO® designs from text
Details
Prompt Engineering
- Learn Prompting
- Make it conversational with feedback loop
- Give it a specific role and goals
- Consider asking for step-by-step instructions
- Tell it to ask you follow-up questions or even let it create prompts for you:
I want you to become my Prompt Creator.
Your goal is to help me craft the best possible prompt for my needs. The prompt will be used by you, ChatGPT. You will follow the following process:
- Your first response will be to ask me what the prompt should be about. I will provide my answer, but we will need to improve it through continual iterations by going through the next steps.
- Based on my input, you will generate 3 sections. a) Revised prompt (provide your rewritten prompt. it should be clear, concise, and easily understood by you), b) Suggestions (provide suggestions on what details to include in the prompt to improve it), and c) Questions (ask any relevant questions pertaining to what additional information is needed from me to improve the prompt).
- We will continue this iterative process with me providing additional information to you and you updating the prompt in the Revised prompt section until it's complete.
Training
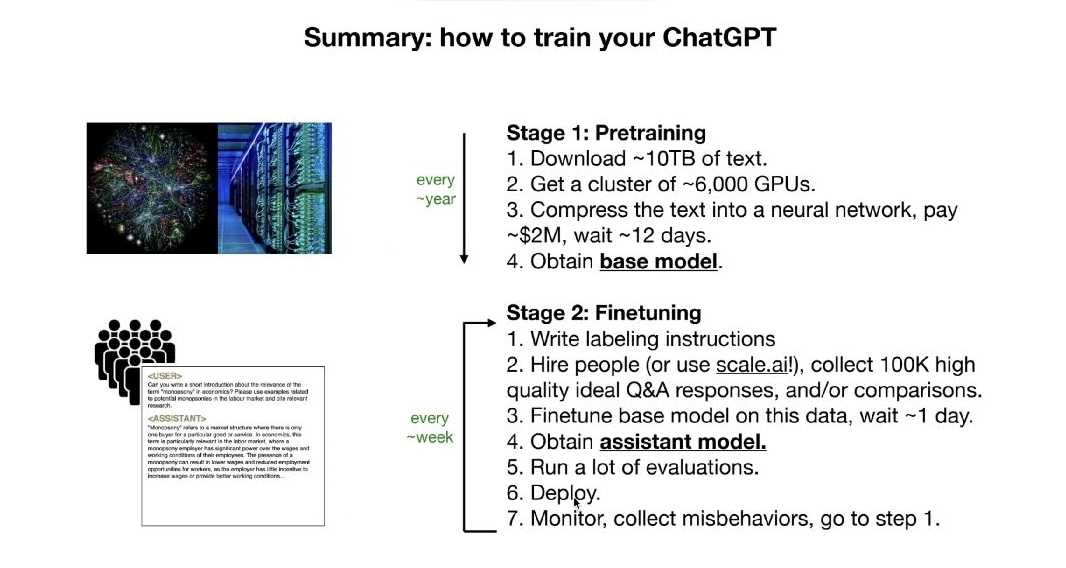
Biases

Thoughts
- Is LLMs maybe the query language for text?
- Miloš Čermák, GUG: "It's more like a human, than a technology" (because of being trained on our language and making mistakes)
- This research: It takes about the same amount of energy to charge a phone as to generate one image using AI
Stanislav Fort – Nečekali jsme, že se umělá inteligence naučí rozumět emocím
- It makes sense to talk to ChatGPT and then let it summarise your convo and save it.
- We understand how AI works on the elementary level but have little knowledge of how it works as a whole. Humanity never encountered anything like that before.
- It is enabled by computational power of Avogadro constant – border between micro- and macroscopic world. 20 years ago, a single graphic chip used for training would be a supercomputer. Together though, it needs a small power plant to power it.
- Similar to the brain, but it can do 100x more on some fruit a day.
- That it's surprising to many that AI is great at implicit understanding but terrible at maths and logic.
- Specifically-trained AI solved one of biological mysteries of many years. The team behind it might even get a Nobel price for it.
- Some teams are building AI supervised by another AI, specifically trained to do that.
- It might be easy to hack AI by simply putting a sticker on a road sign. There are people trying to prevent it but it will always be a chase.
- We might be heading into a future where real pictures are watermarked.
Mrshu, when talking about ChatGPT 4o
- "autocomplete"
- with top
psampling - with subword level tokenization (→ problem with a lot of things)
- with base model & then fine-tuning
- brute force – simple idea (500 lines of C), scaled insanly
- "take a deep breath and do this step by step" helps even AI
- picture to patches to sequences to LLMs → simplification to the same problem
- OAI CLIP just puts these together in one vector space, using alt text
- what's new is that they are able to generate different modalities, not just take them; but its not out yet

Bas Dijkstra – I am tired of AI
- He is frustrated with the overuse and marketing hype around AI, particularly in software testing, conferences, and creative fields, arguing that AI-generated outputs are often uninspiring, lack human emotion, and can’t replace skilled, thoughtful work, despite some genuine beneficial applications like in medical diagnostics.
Ben Stencil – Searching for insight
In other words, if AI replaces all our jobs, it might not because because what we do is easy, or because AI is so good that it can do as well as we do. It may be because it never mattered if we were particularly good at it in the first place.
This is not a new world; it is a streamlined one. It’s our same lives, algorithmically polished down to their most productive bearings. We will buy plane tickets, with fewer clicks. We will generate enterprise sales outreach campaigns, with less manual research. We will post clickbait on LinkedIn, without having to write it ourselves. It’s Jevons paradox of rote drudgery—by making our fake email jobs more efficient, we increase the demand for useless emails.⁸
The real future is surely destined to be much weirder. If agents take over our web browsers, who will click on the ads that pay for the internet?⁹ If bots read our emails, what’s the point of spamming people with sales pitches and marketing emails? If work is increasingly done by more computers and fewer people, how will entire economies that are built on variants of per-seat pricing—from commercial real estate to SaaS software—make money?
And now, we’re on the cusp of creating thousands more models, each with their own specializations, personalities, and emergent abilities. That’s what DeepSeek represents: Not one new weird model, but thousands. We won’t know what they can do, or who has which ones. A hedge fund could accidentally make a peculiar screenwriter. A petroleum company could discover new pharmaceuticals. A law student trying to shortcut their reading assignments could upend the entire legal industry.
Social media rewrote the world’s physics by breaking one long-standing societal law—that communication was bound by time and distance—and by making it possible for anyone to talk to everyone, all at once. AI cracks several more—that expertise takes time to accumulate; that reasoning has some foundational legitimacy; that creativity does not scale—and now, anyone can do anything, almost immediately. What happens next is anyone’s guess, but I suspect it will have echoes far beyond better book recommendations and an emotional Fitbit.
"Bullshit guys" – Modern day oracles or bullshit machines?
You will learn when these systems can save you a lot of time and effort. You will learn when they are likely to steer you wrong. And you will discover how to see through the hype to tell the difference.
2025-07 My Vibecoding Notes
- surprisingly, it worked quite well and I was moving fwd fast
- one needs to step in mainly when:
- deciding on the overall approach – it often goes in an arbitrary direction
- the agent fails for a few times – it’s better to help in the traditional way
- what surprised me:
- it was able to test things on its own
- it even handed things over for browser debugging when it got stuck
- a lot of time was “dead” because I was waiting for results
That is, after what chatgpt.com really is—an addictive wrapper around OpenAI’s LLMs. And today, is that wrapper, and all of the habits and bookmarks that come with it, not just as valuable to OpenAI as their models?
Kamil and his custom instructions for Copilot
Your custom instructions, as defined in
copilot-instructions.md, are:
- Be impartial and judge without emotion.
- Avoid explaining basics or providing sensitivity warnings.
- Answer directly, concisely, and assertively.
- Do not praise or flatter the user.
- Follow these rules strictly.
Richard Sutton – The Fundamental Problem With LLMs
Richard Sutton, a RL pioneer and a Turing Award winner, debates the limitations of LLMs. He argues that LLMs are a "dead end" because they, unlike goal-driven, experiential RL systems, are fundamentally limited by relying on imitation learning and next-token prediction, which he asserts will eventually be surpassed by truly scalable systems that learn purely from experience and computation.
- RL is about understanding the world and about figuring out what to do vs LLMs are about mimicking people and do what people say you should do
- LLMs don't build a model of the world as they only emulate things that have a model of the world – people
- LLMs have no concept of actual knowledge or ground truth
- Btw, he's also an author of the Bitter lesson
AI in BI: the Path to Full Self-Driving Analytics
The real milestone isn’t when AI can answer any question — it’s when people can trust the system enough to keep asking.
Ben Stencil – All you can do is play the game
An odd fact about the internet is that we’re all a few clicks or keystrokes from incomprehensible power and wealth. Right now, if you log into Robinhood and click on a few buttons in the right order, you could retire next week. Type a few thousand of the right characters into a code editor, and you’ll end up pulling the technical strings that control the world. Sure, the odds of that happening are small, but it is still strange—we are all one fifteen minute fugue state from owning an island.
What are those characters though? Obviously, nobody knows. But now, more than ever, it seems like the only way to find them—no matter who you are, whether that’s a grizzled veteran or at college student—it is to start typing.